Qu’est-ce que l’Edge Computing ?
L’Edge Computing est une architecture informatique qui permet le traitement en temps réel des données au plus près de leur source. Cette approche s’appuie notamment sur le principe de data locality, elle limite le recours à un data center centralisé ou au cloud pour certaines opérations critiques.
Cette approche répond à l’augmentation des données en temps réel produites par des systèmes connectés, notamment dans les environnements IoT. L’Edge Computing vise à améliorer la réactivité des applications et à réduire la latence.
Ces enjeux sont devenus stratégiques pour de nombreux usages professionnels. Selon un rapport Statista publié en décembre 2025, le marché mondial du edge computing devrait atteindre 350 milliards de dollars de chiffre d’affaires d’ici 2027.
Il est donc important de comprendre : Qu’est-ce que l’Edge Computing ?

À quoi correspond l’Edge Computing ?
Le principe fondamental du Edge Computing
Le principe d'Edge Computing repose sur une logique où les systèmes traitent les données localement, directement à proximité des équipements qui les génèrent. Les données produites par les équipements sont traitées directement sur site, sans être envoyées systématiquement vers un data-center centralisé.
Mettre en place cette approche décentralise le traitement des données. Elle facilite la prise de décision, adaptée aux usages critiques. Elle limite aussi les échanges inutiles avec des centres de données centralisés, tout en préservant la connectivité globale du système.
Les principes du Edge Computing :
- Traitement décentralisé au plus près du terrain ;
- Décisions en temps réel basées sur des données locales ;
- Réduction des flux vers le cloud.
En quoi l’Edge Computing se distingue du cloud computing ?
L’Edge Computing ne remplace pas le cloud computing, il le complète. Le cloud repose sur des infrastructures informatiques centralisées, conçues pour mutualiser des ressources informatiques à grande échelle via des services cloud.
Dans un modèle cloud, le traitement s’effectue dans des data-centers distants. Cette architecture est adaptée au stockage massif, à l’analyse globale et à l’exploitation centralisée des données. En revanche, elle dépend fortement de la connectivité réseau.
L’Edge Computing permet de répartir le traitement des données entre les équipements de terrain et les systèmes centralisés. Il s’intègre aux architectures existantes pour optimiser la répartition des charges de travail de calcul entre edge et cloud.
Cette complémentarité permet d’exploiter pleinement les infrastructures existantes. Elle améliore la performance globale des systèmes sans remettre en cause les services cloud déjà en place.
Comment fonctionne une architecture Edge Computing ?
Les composants d’une architecture Edge
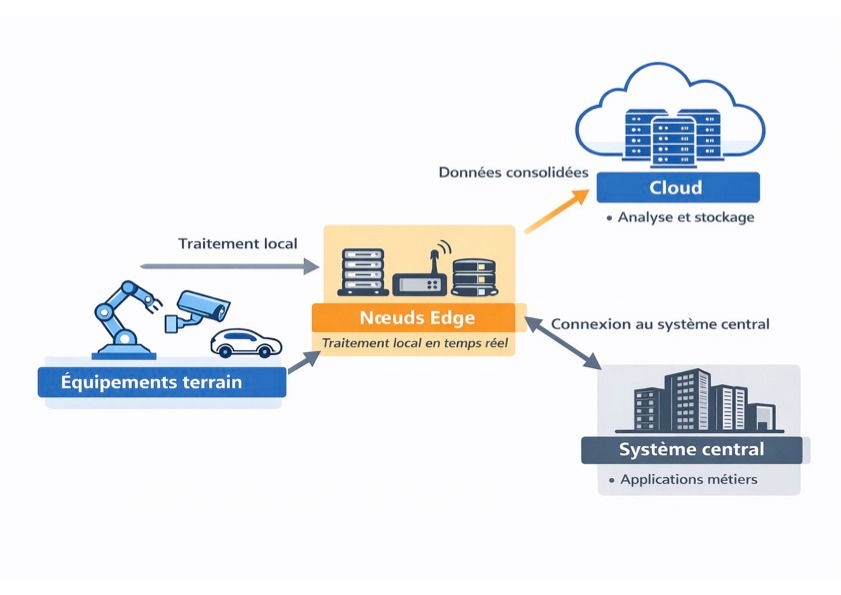
Une architecture Edge Computing organise le traitement des données entre les équipements de terrain, un réseau local et des systèmes centralisés. Elle s’appuie sur une infrastructure informatique distribuée, connectée à l’infrastructure réseau existante.
Concrètement, elle repose sur trois composants fonctionnels :
- Les équipements terrain, qui produisent les données brutes au plus près des usages. Ces données sont immédiatement transmises vers un réseau local.
- Les nœuds Edge, positionnés sur ce réseau local, assurent le traitement des données. Ils analysent les flux, exécutent les applications et décident si les données doivent être exploitées localement ou transmises.
- La connexion vers un cloud ou un système central, utilisée lorsque les données doivent être agrégées, stockées ou analysées à plus grande échelle.
Cette transmission s’effectue via les routeurs de l’infrastructure réseau, selon des règles définies à l’avance.
Cette organisation permet de diriger les données soit vers un traitement local, soit vers le cloud, selon les besoins métiers. Elle autorise un déploiement progressif du Edge Computing, sans remise en cause de l’architecture existante.
Le rôle des nœuds Edge
Les nœuds Edge sont les éléments qui exécutent le traitement local des données. Ils reçoivent les flux issus des équipements terrain et prennent en charge les opérations nécessaires.
Sur ces nœuds Edge, les applications sont exécutées localement. Elles peuvent être isolées via la virtualisation ou la conteneurisation, selon les besoins. L’orchestration de ces composants permet de gérer dynamiquement le déploiement, la mise à jour et la répartition des charges applicatives sur les différents nœuds Edge, en fonction des contraintes opérationnelles.
Les données traitées sont ensuite soit conservées localement, soit transmises vers le cloud. Cette transmission dépend des règles définies par l’architecture et les usages métiers.
Pourquoi l’Edge Computing est devenu stratégique ?
Les différents avantages de l’Edge Computing dynamisent ce marché, à tel point que les investissements mondiaux dans l’Edge Computing dépassent 50 milliards de dollars, selon Gartner en 2025. Cette mouvance s’explique par des enjeux opérationnels concrets liés à la performance, aux coûts et à la sécurité des systèmes numériques.
Réduction de la latence et traitement en temps réel
L’Edge Computing permet de réduire la latence réseau en rapprochant le traitement des données des usages. Cette proximité améliore directement le temps de réponse des systèmes.
Cette capacité est indispensable pour des applications critiques qui nécessitent des décisions immédiates et une haute-disponibilité continue. Elle concerne notamment des cas d’usage où chaque milliseconde compte, comme :
- l’automatisation industrielle ;
- la vidéosurveillance intelligente ;
- les véhicules connectés.
Optimisation des flux de données et des coûts réseau
L’Edge Computing limite les volumes de données transmis vers le cloud. Une partie des charges de travail est traitée localement, avant toute remontée éventuelle.
Cette approche réduit la consommation de bande-passante. Elle entraîne aussi des réductions de coûts liées aux transferts réseau. La performance globale du système est améliorée, avec une meilleure résilience opérationnelle ainsi qu’une tolérance aux pannes plus importante.
Renforcement de la sécurité et de la conformité
Le traitement local des données à la périphérie du réseau limite leur exposition lors des échanges externes. Il réduit les risques liés aux transferts massifs vers des infrastructures distantes.
Cette approche est particulièrement adaptée aux environnements soumis à de fortes contraintes de sécurité. Elle facilite aussi la supervision des flux et contribue à une meilleure efficacité énergétique des systèmes.

Quels sont les principaux cas d’usage du Edge Computing ?
Les cas d’utilisation de l’Edge Computing couvrent un large éventail d’applications professionnelles. Il vise à aider les entreprises à exploiter leurs données au plus près des usages, dans des environnements distribués et contraints.
Edge Computing et Internet des objets (IoT)
L’Edge Computing est particulièrement adapté aux environnements IoT, où des milliers d’équipements connectés à internet génèrent des données en continu. Le traitement local permet de réagir immédiatement, sans surcharge des réseaux centraux.
Il est notamment utilisé pour :
- des capteurs industriels produisant des données en continu ;
- des infrastructures connectées intégrées aux infrastructures réseau existantes ;
- des smart buildings pilotés par des systèmes d’information locaux.
Edge Computing dans l’industrie et les environnements critiques
Dans l’industrie, l’Edge Computing permet des décisions opérationnelles immédiates. Il réduit la dépendance à une connexion cloud permanente et sécurise les processus critiques. Ces usages sont fréquents dans les secteurs de la production, de l’énergie et des télécommunications.
Edge Computing et intelligence artificielle embarquée
L’Edge Computing permet d’exécuter des modèles d’IA directement sur site. En exécutant les traitements localement, cela facilite la maîtrise des données sensibles et limite leur exposition à des infrastructures tierces.
Il est utilisé pour :
- l’analyse des données vidéo en temps réel,
- la détection d’anomalies sur des flux continus,
- l’IA embarquée sur des machines ou des équipements ou même des véhicules autonomes.

Conclusion
L’Edge Computing s’intègre naturellement aux réseaux existants dans une logique d’architecture cloud hybride. Il permet de combiner traitement local et exploitation centralisée, selon les contraintes métiers.
Cette approche facilite les mises à jour des systèmes distribués et renforce l’agilité des organisations. Elle s’inscrit pleinement dans une démarche de transformation numérique, en adaptant les architectures aux usages terrain sans remettre en cause l’existant.
FAQ
L’Edge Computing remplace-t-il le cloud computing ?
Non. L’Edge Computing complète les services de cloud computing existants. Il traite certaines données localement, tandis que le cloud computing reste adapté au stockage et aux analyses centralisées.
L’Edge Computing est-il réservé aux grandes entreprises ?
Non. S’il est largement utilisé par les grandes entreprises, l’Edge Computing et l’Edge Computing multi-accès (MEC) s'adaptent aussi à des structures plus modestes. Il peut être déployé progressivement, sans nécessiter des infrastructures dédiées complexes.
Quelle différence entre Edge Computing et Fog Computing ?
L’Edge Computing traite les données au plus près des équipements. Le Fog Computing s’appuie sur une architecture hybride, avec des niveaux intermédiaires. La différence tient principalement au modèle de déploiement.
L’Edge Computing améliore-t-il la sécurité des données ?
Oui, l’Edge Computing améliore la sécurité et la confidentialité des données sous certaines conditions. Le traitement local limite les échanges réseau et réduit l’exposition des données. Il contribue à des données mieux sécurisées et à une meilleure protection des données, sans remplacer les politiques de sécurité existantes.
Plus de contenus
Ransomware : définition, fonctionnement et protection pour les entreprises
Catégorie
Qu'est-ce que l'AIOps ?
Catégorie
Ransomware : définition, fonctionnement et protection pour les entreprises
Catégorie